Language Conversions
Datatek’s Language Conversion Process
In Brief
Our language conversion process is an iterative process. In general, the code, including copybook/include/macro files, is parsed (similar to that of a compiler) and then a logical model of the program is built - a model which includes all of the comments and other white space. This information is then correlated with other modules and the appropriate modifications for handling the differences between the source and target programming languages are made. Information needed for other modules is then extracted to feed into the conversion of other source code modules, creating a “cross pollination” effect which ensures that specific information about a module is carried through the entire conversion process code base. The code is then generated.
Process Diagram
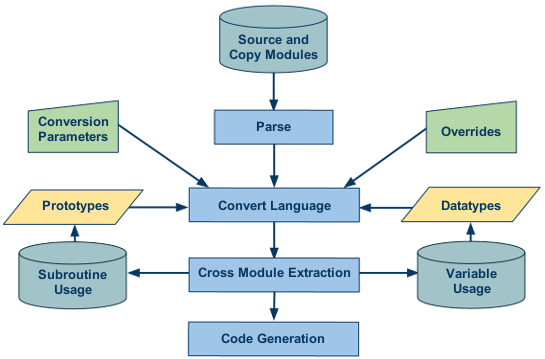
The diagram above is an abstraction that represents both single and multiple runs of a module through the tool. Because certain kinds of data can only be gained in an iterative fashion, each successive run of the tool gathers and stores additional information during each stage. This provides the ability to perform complex code manipulations and conversions resulting in better and more maintainable converted code.
The Conversion Process in More Detail
As can be seen in the diagram above, the process begins with the parsing of a source file and its copy/include/macro modules into an internal model. The parsed information is fed into the language converter along with additional information that may be pertinent to the conversion, including data types, prototypes, conversion parameters, and overrides:
Data Types
Data type information is required in cases where the source language to the target language does not have a specific mapping. For instance, in COBOL character strings are blank filled, but in C they have a NULL byte at the end. In some cases, in a COBOL to C conversions the character string requires a one byte expansion. In others, the field stays the same length as in COBOL. The usage in other modules would determine the proper handling of the field across the whole application. In cases where the target is an object-orientated language, information about the new classes being created will be fed into the conversion process.
Prototypes
Prototype information allows parameter information to be available for target languages that require it. For example, a target language might require parameters to match the parameters that the called routine expects, but it does not implement the same implicit conversion that the source language performed.
Conversion Parameters
Conversion parameters provide information to the converter so that it produces code that matches the customer's coding style or which is dependent upon knowledge outside of the scope of the language. For example, in migrating to a new platform, the length of process id's might need to be expanded from two bytes to four.
Overrides
Functionality overrides provide the ability to bypass or modify functional behavior. For instance, file pathname may need to be remapped because of a desire to have a different file system layout than was used in the source environment.
To fully correlate the information from the application, the information is extracted from a given module multiple times. This is required to make certain that the whole application is converted consistently. For example, variable passing and the proper conversion of specific variables can then impact other variables in the program through assignments and other uses. Those other variables will then be converted differently which might result in changes to yet another variable in the application.
The conversion process then must be iterative. With each successive pass through the entire code set, additional information is generated, since a change to one module can create the domino effect of requiring modifications in other modules. Changes to those modules, can then require modifications to another set of modules, and so on. By having the ability to quickly and repetitively parse through entire code sets, it is clear that Datatek’s automated language conversions are the most cost effective and reliable way to consistently convert between programming languages.
Next Step
Learn about the Advantages of Datatek's Automated Language Conversions
Success Stories
Fortune 1000 Financial Services
A Fortune 1000 financial software and data center services provider wanted to migrate from their legacy platform to an Open System environment. Their software suite was written in a combination of PL/I, Assembler ...
Read more about this and other successes »
More Information
- Conversion Overview
- Conversion Process
- Conversion Advantages
- Resources & White Papers
- Frequently Asked Questions
- Success Stories
Source Languages
Strategic Partners

How Can We Make This Website Better?
If you’ve discovered a mistake, an ambiguity, or that some important information is missing from this website, please let us know.
© Copyright Datatek, Inc. 1994-2026, All rights reserved. All trademarks belong to their respective owners.